
老规矩:秉承不泄露公司信息的原则(kettle操作hadoop,敬请期待)
3 ETL操作
3.1 数据抽取
面对不同的数据源,kettle对不同的数据源的抽取方式可分为以下几个方式:
3.1.1文件抽取
Kettle可以将文本文件、excel文件、xml文件、Json文件等一系列文件作为数据源。以文本文件为例,演示kettle文件抽取过程。
文件抽取过程可分为两种方式:
a. 直接添加文件
整个流程如图3.1所示。
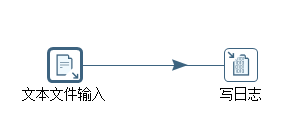
图3.1 从本地直接操作文本文件
此方式采取直接添加文件路径的方式,直接操作文本文件,如图3.2所示。首先,点击“浏览”选择本地的文本文件,然后点击“增加”,将所选文件添加到“选中的文件中”。然后,点击“内容”和“字段”等选项卡来设置将要输入的数据内容。如图3.3、3.4所示。
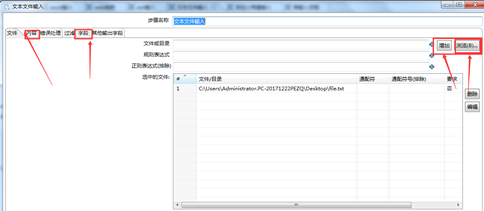
图3.2 直接添加文本文件
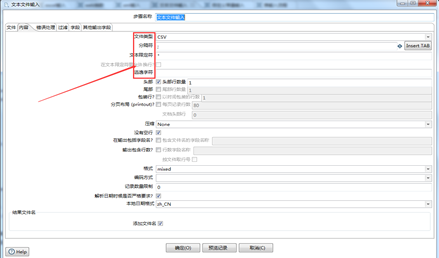
图3.3 设置输入内容的格式
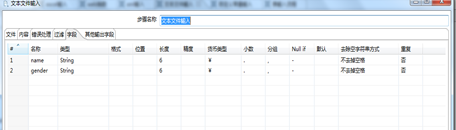
图3.4 选择需要输入的字段
b. 从上一个步骤获取文件名
整个流程如图3.5所示。首先“自定义常量”节点定义好文件名,然后传输给“文本文件输入”节点,同时,设置好两个节点相关参数,最后在控制台以日志的形式输出。参数设置如图3.6-3.8所示。
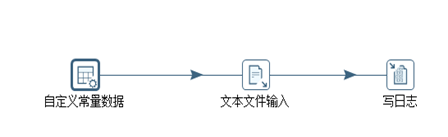
图3.5 从上一步获取文件名
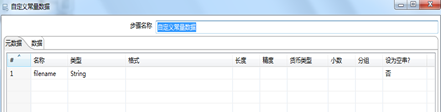
图3.6 自定义常量节点定义字段名
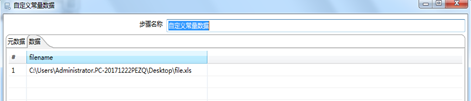
图3.7 自定义常量节点定义文件名(字段内容)

图3.8 文本文件输入节点定义连接参数
文本文件节点剩下的设置与上一步一样。
3.1.2 数据库抽取
数据库抽取的目的,是将源数据库的数据和目标数据库的数据做迁移。它的基本流程如图3.9所示。
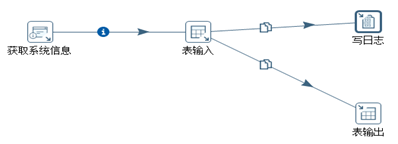
图3.9 数据库抽取流程
首先从“获取系统信息”节点中获取当前系统时间,然后传输给“表输入”节点,然后表输入节点以复制的方式![]() 将查询结果发送给“写日志”节点和“表输出”节点。表输入和表输出的配置如图3.10和图3.11所示。
将查询结果发送给“写日志”节点和“表输出”节点。表输入和表输出的配置如图3.10和图3.11所示。
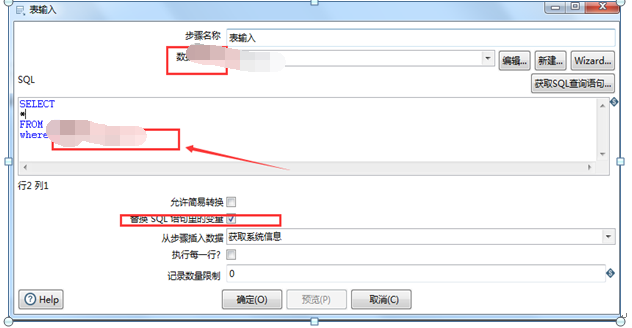
图3.10 表输入设置
“数据库连接”设置源数据库连接,勾选“替换SQL语句里面的变量”,SQL语句里面的“?”代表上一个节点传递过来的参数。
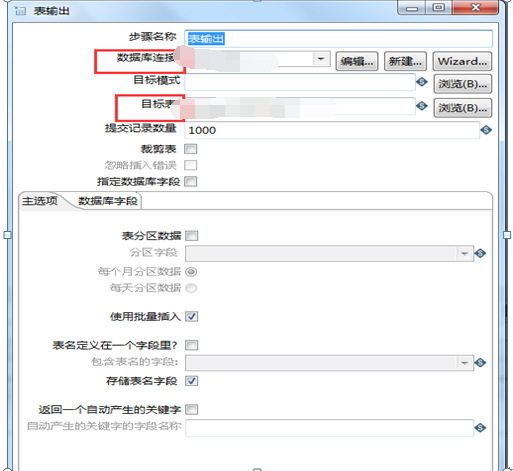
图3.11输出表节点的设置
3.1.3 web数据抽取
以将所示。首先,通过“生成记录”节点传入所要抽取的天气信息的城市名,本例设置为“武汉”,然后通过“web服务查询”将抽取的天气数据以复制的形式发送给“xml输出”和“文本文件输出”节点。“生成记录”和“web服务查询”设置如图3.13-3.16所示。
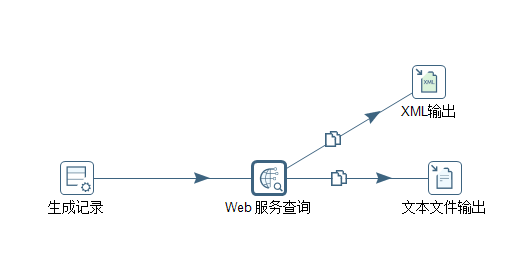
图3.12 web数据抽取流程
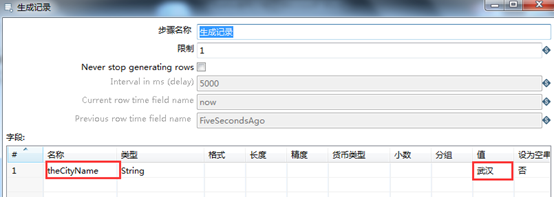
图3.13 生成记录节点设置
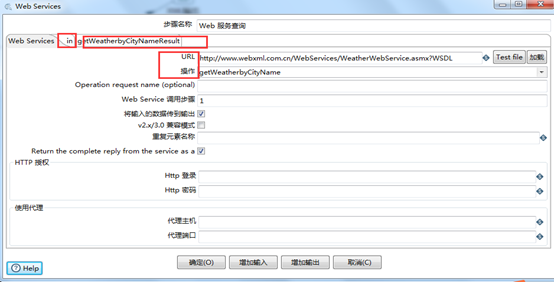
图3.14 web服务查询的设置
点击“增加输入”和“增加输出”编辑图3.14中的“in”和“getWeatherbyCityResult”选项卡。设置如图3.15和3.16所示。
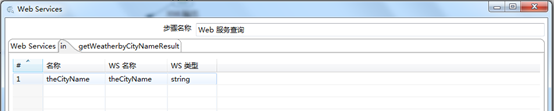
图3.15 web服务查询输入设置
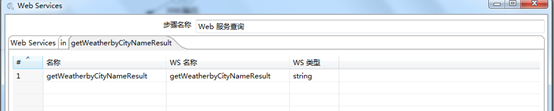
图3.16 web服务查询输出设置
3.2 数据清洗和校验
3.2.1 计算器/空值处理
(1)计算器
“计算器”可以执行字段之间的从加减乘除、求余、开方等数学操作,也可以对字符类型,时间类型的字段进行相应的操作,还可以进行模糊匹配等操作,具体功能见图3.17。
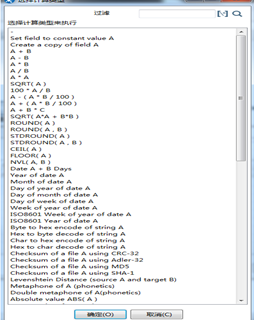
图3.17 计算器控件的详细功能
此处举一个例子来说明“计算器”的功能:产生100个0-100的随机数,以50为界限,将100个数分为两组,统计每组数据的个数,最后合并,输出两组个多少个数。脚本如图3.18所示。
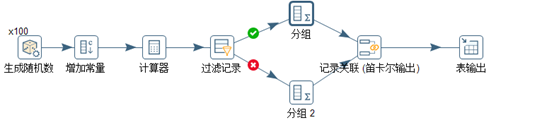
图3.18 计算器用例
首先“生成随机数”产生100个0-1的随机数random,然后“增加常量”计入a1=50,a2=100两个常量,通过计算器将a2余random的乘积给a3,然后通过“过滤记录”将<=50的分为一组,另外的分为一组,最后通过“记录关联”将两组数据关联输出到目标表。
(2)空值处理
对于数据中的空值可以通过“替换NULL值”和“设置值为NULL”来将字段中null值替换为指定字符或将指定字段的值设定为null。
3.2.2 字符串替换/操作/剪切
(1)字符串剪切
字符串剪切的目的是将字符串字符串之中的信息截取出来赋给新的字段,需定义需要剪切字符串的其实位置和结束位置,具体操作如图3.19。
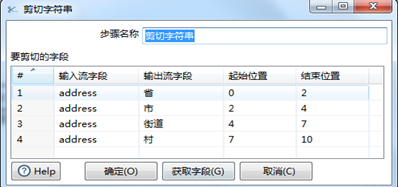
图3.19 字符串剪切
(2)字符串操作
目的是对目标字符串的内容江西大小写替换,填充,首字母大写,只显示数字,移除特殊字符等操作,如图3.20所示。
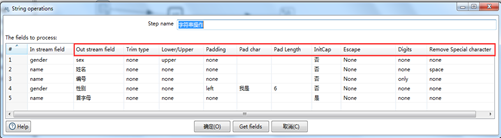
图3.20 字符串操作种类
(3)字符串替换
目的是将目标字段里面的字符串用替换为指定字符串。使用方法如图3.21。
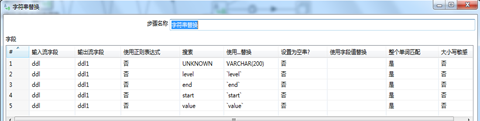
图3.21 字符串替换
3.2.3 字段值替换/替换为常量/拆分字段
(1)字段值替换
目的将两个指端之间的值相互替换。操作如下;
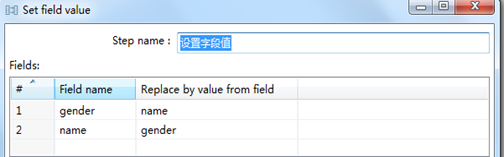
图3.22 字段值替换
(2)替换为常量
将字段的值替换为设定好的常量值,操作如下。
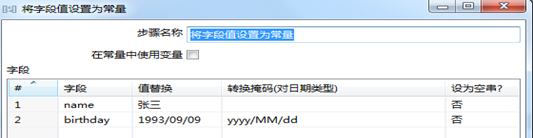
图3.23 字段值替换为常量
(1) 拆分字段
可以按照指定的分隔符将字段的值拆分多列。操作如图3.24.
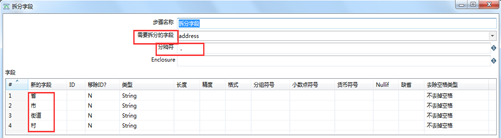
图3.24 拆分字段
3.2.4 字段拆为多行/列转行/字段选择
(1)字段拆为多行
可将字段按照指定分隔符拆分为多行。具体操作和结果如图3.25所示。
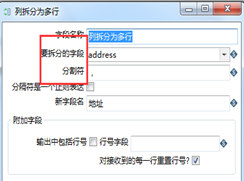
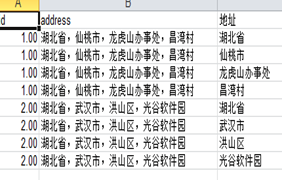
图3.25 字段拆分多行
(2)列转行和字段选择
此出以一个实例来介绍这两个控件的功能。利用“列转行”控件一个字段的数据按照另一个字段分组转换为多列。利用“字段选择”控件控制想要输出的的字段数据。具体kettle脚本如图3.26所示。
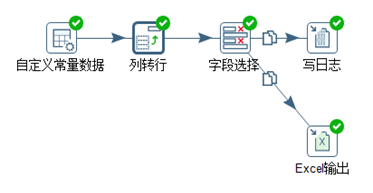
图3.26 列转行
自定义常量的数据如图3.27所示,利用“列传行”将“星期”这个字段按照“姓名”分组,并将“星期”转化为7列,入图3.28所示。同时通过“字段选择”控件控制不输出“周二”这一列,如图3.29所示。
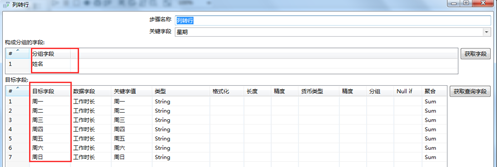
图3.28 列转行
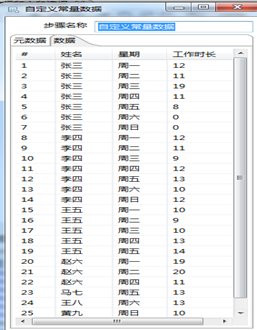
图3.27自定义数据
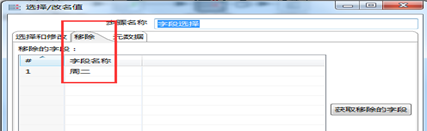
图3.29 移除字段周二
3.2.5 过滤记录和值映射
过滤记录:筛选出满足条件的数据。
值映射:改变指定指端的值为特定的值。
以orders表为数据源,对表进行过滤和值映射,脚本如图3.30所示。
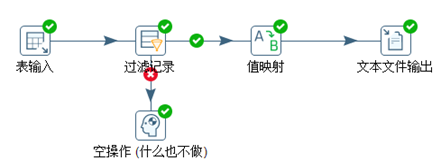
图3.30 过滤记录和值映射
设置过滤条件:筛选出owner_phone=17764039907的数据,true时执行值映射,false什么都不做。如图3.31所示。
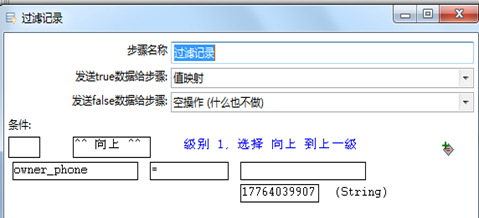
图3.31 过滤条件设置
设置值映射:改变driver_name。如图3.31所示。
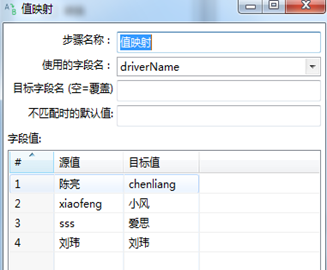
图3.31 值映射设置
最后将结果输出给文本文件。
3.2.6 模糊匹配
将两张表的包含有相似信息的字段做匹配,有不同的匹配算法,效果各不相同。
自建两张表source和sample,同时输入给模糊匹配,对店名做匹配,结果输出到日志。脚本如图3.32所示,表样如图3.33所示,模糊匹配设置如图3.34所示。选取jaro匹配算法,结果见图3.35。
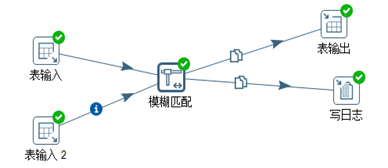
图3.32 两表字段模糊匹配
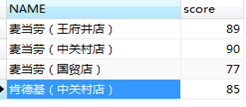
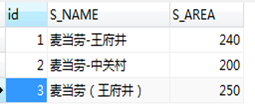
图3.33 两表数据
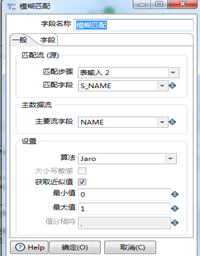
图3.34 模糊匹配设置
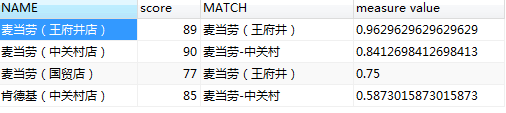
图3.34 模糊匹配结果
3.2.7 数据校验/流查询
数据校验一般是通过参照表来做数据的查询和检验的。提供一个输入字段,如果输入字段里面的值没有匹配上,就给对应的数据行做一个错误标志。以使用城市和邮政编码查询做例子,演示如何使用“计算器”控件和“流查询”控件来判断地址和邮政编码是否匹配,具体转换脚本如图3.35。
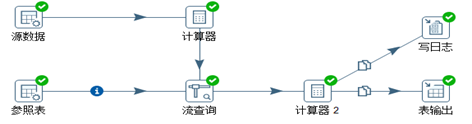
图3.35 数据校验
首先没使用两个“自定义常量数据”来制定参照表和查询表。如图3.36所示。然后通过一个计算器Return only digits from string A功能将源表的postcode从字段数据中分离出来赋给新的字段,传输给“流查询”,如图3.37所示。然后使用“流查询”步骤从参照表中查询城市名称。为了后面再处理没有查询到的数据,建议在查询失败时,使用一个容易识别的默认值,图3.38显示了完整的流查询步骤,这里设置的查询失败的默认值是“***unknown***”。最后,使用另一个计算器步骤,把City和returnCity作为字段A和字段B,使用Jaro-Winkler匹配算法,把新生成的字段命名为cityscore,也就是数据校验的得分。
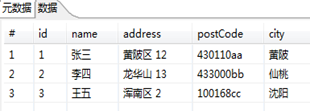
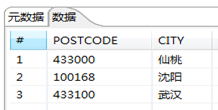
图3.36 查询数据和参照表
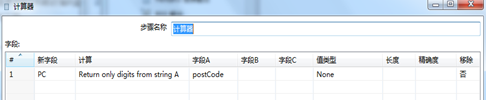
图3.37 获取源表邮编
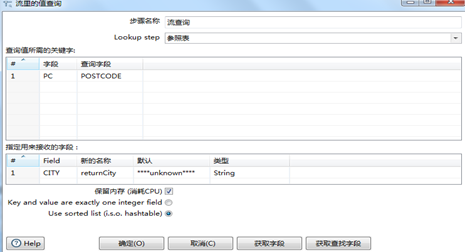
图3.38 数据校验设置

图3.39 模糊匹配评判数据校验得分
3.2.8 插入/更新/删除
(1)插入/更新
作用:实现新表和历史表的数据同步。
转换脚本,如图3.40所示,“插入更新”设置见图3.41,主键不用更新。
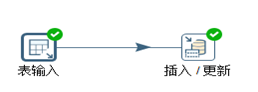
图3.40 插入更新
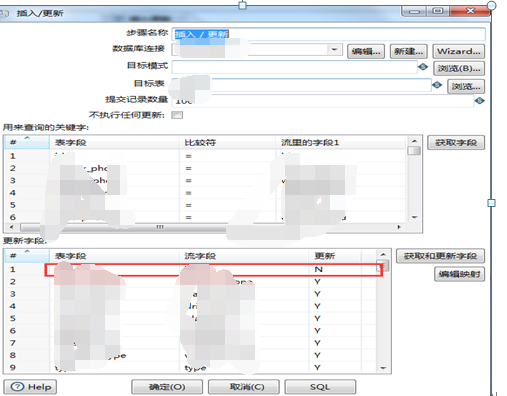
图3.41 插入更新配置
(2)删除
删除满足要求的数据。转换脚本见图3.42。
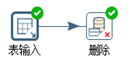
图3.42 删除满足要求的表数据
3.2.9 排序记录/分组
(1)orders表为源数据,针对enterprise_id排序,不分组取topN。转换脚本如图3.43所示。
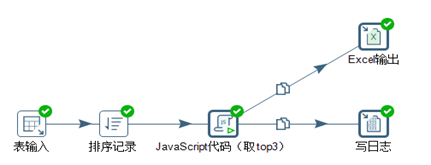
图3.43 不分组排序取top3
“排序记录”的排序字段设置为“enterprise_id”,见图3.44。提取top3的JS代码见图3.45。
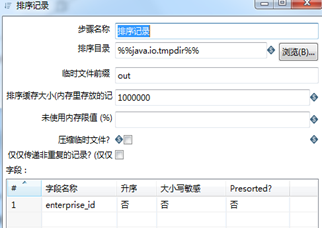
图3.44 排序字段设置
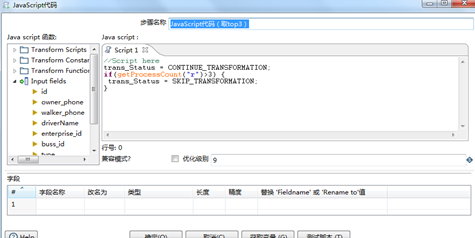
图3.45 提取top3的JS脚本
SKIP_TRANSFORMATION,ERROR_TRANSFORMATION, CONTINUE_TRANSFORMATION是TRANSFORMATION已经预先定义好的静态常量,不可更改,作用是过滤记录行,控制转换流程。getProcessCount("")方法在kettle是一个特殊的函数,含义和参数解释spoon官方解释:
// Returns a number with the current processed Rows.
// The type is changable.
// Usage:
// getProcessCount(var);
// 1: String - The Pentaho/Kettle Type:
// u - Lines Update
// i - Lines Insert
// w - Lines Write
// r - Lines Read
// o - Lines Output
(2) orders表为源数据,针对enterprise_id排序,分组取topN,就是每个enterprise取topN。转换脚本见图3.46。
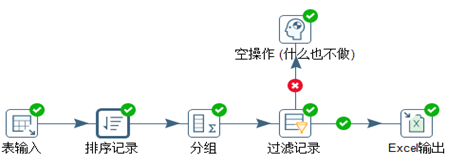
图3.46 排序分组取top3
排序配置与上一个例子一样,分组配置见3.47,每个组加一个行号字段,为后续过滤数据做准备。
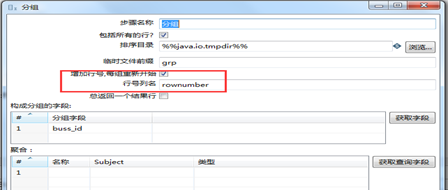
图3.47 分组设置
“过滤记录”的作用是筛选出每组的top3,配置见图3.48。
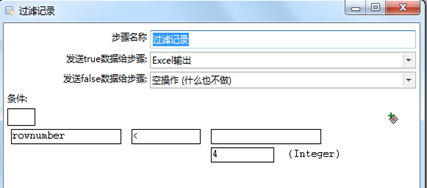
图3.48 提取每组的top3
3.2.10 去重复记录
目的:去除重复行,转换脚本见图3.49。
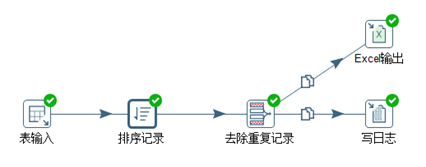
图3.49 去重重复行
“去重复记录”配置见图3.50。字段为需要检查是否包含相同的信息。加入一个新字段count,记录重复记录的数量。
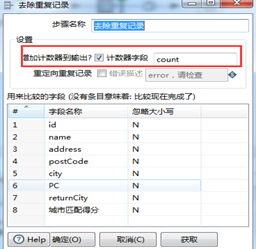
图3.50 去重配置
3.2.11 left 、inner、right、full Join/union
关联查询和合并操作都可以使用“执行sql脚本”控件来实现,但是同样也可以使用控件来实现。
(1) left join
a、left join操作可以使用“数据库查询”来实现的。转换脚本如图3.51所示。
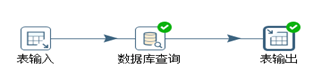
图3.51 left join实现
自定义两张表employee和departments如图3.52所示。
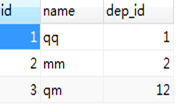
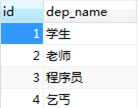
图3.52 被查询表
“数据库查询”的设置见图3.53,关联id和dep_id两个字段。
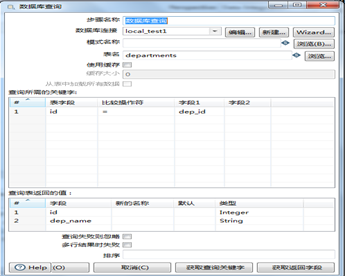
图3.53 数据库查询设置
b、jion全套操作也可以使用“记录集连接”实现。转换脚本见图3.54,其输入数据流必须是排好序的。配置见图3.55。inner/left/right/full可选。
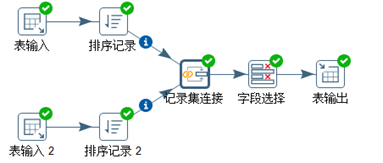
图3.54 join全套操作脚本
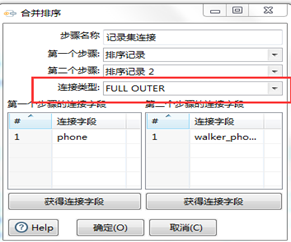
图3.55 记录集连接设置
(2) Union
将查询的不同数据库的两张表的结果合并在一起,转换脚本见图3.56。
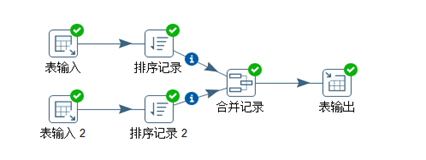
图3.56 union操作
注意:输入“合并记录”的数据必须先排好序。合并记录的配置见图3.57。
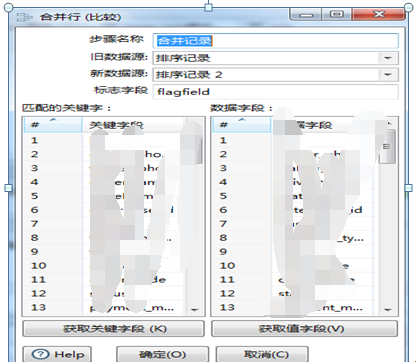
图3.57 合并设置
注意:秉承不泄露公司信息的原则